

Imaginez-vous en train de taper une « musique d’introduction dramatique » et d’entendre une symphonie envolée ou d’écrire des « pas effrayants » et d’obtenir des effets sonores de haute qualité. C’est la promesse de Stable Audio, un modèle d’IA texte-audio annoncé mercredi par Stability AI qui peut synthétiser la stéréo 44,1 kHz musique ou sons provenant de descriptions écrites. D’ici peu, une technologie similaire pourrait mettre les musiciens au défi dans leur travail.
Si vous vous souvenez bien, Stability AI est la société qui a contribué à financer la création de Diffusion stableun modèle de synthèse d’images à diffusion latente sorti en août 2022. Non contente de se limiter à la génération d’images, l’entreprise s’est diversifiée dans l’audio en s’appuyant sur Harmonieun laboratoire d’IA qui a lancé le générateur de musique Diffusion de danse en septembre.
Désormais, Stability et Harmonai souhaitent se lancer dans la production audio commerciale d’IA avec Stable Audio. A en juger par échantillons de productioncela semble être une amélioration significative de la qualité audio par rapport aux précédents générateurs audio IA que nous avons vus.
Sur sa page promotionnelle, Stability fournit des exemples du modèle d’IA en action avec des invites telles que “bande-annonce épique, percussions tribales intenses et cuivres” et “lofi hip hop beat mélodique chillhop 85 bpm”. Il propose également des échantillons d’effets sonores générés à l’aide de Stable Audio, comme un pilote de ligne parlant via un interphone et des personnes parlant dans un restaurant très fréquenté.
Pour former son modèle, Stability s’est associé à un fournisseur de musique de stock AudioSparx et a autorisé un ensemble de données « composé de plus de 800 000 fichiers audio contenant de la musique, des effets sonores et des tiges d’instrument unique, ainsi que des métadonnées de texte correspondantes ». Après avoir introduit 19 500 heures d’audio dans le modèle, Stable Audio sait comment imiter certains sons qu’il a entendus sur commande, car ces sons ont été associés à des descriptions textuelles au sein de son réseau neuronal.
IA de stabilité
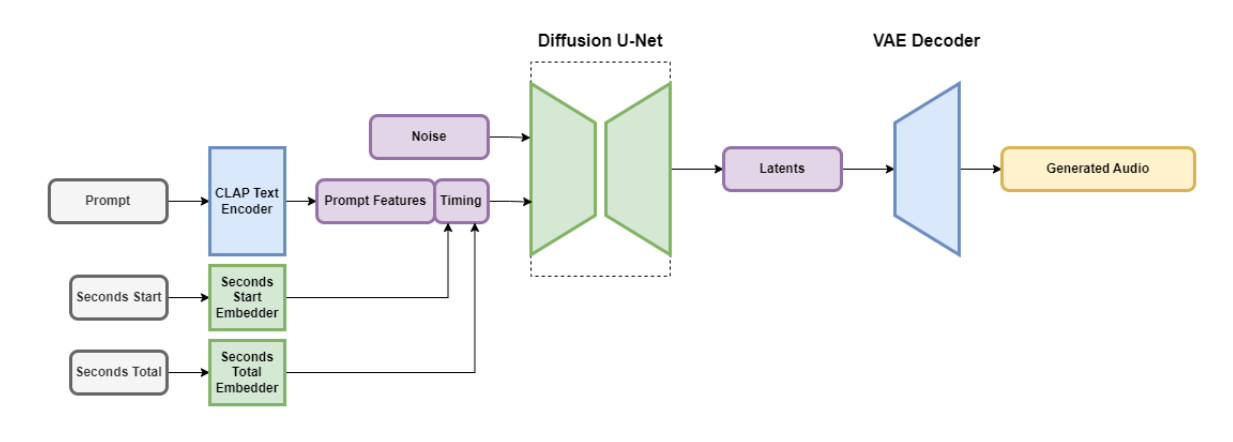
Stable Audio contient plusieurs parties qui fonctionnent ensemble pour créer rapidement un son personnalisé. Une partie réduit le fichier audio de manière à conserver ses fonctionnalités importantes tout en supprimant le bruit inutile. Cela rend le système à la fois plus rapide à enseigner et plus rapide à créer de nouveaux fichiers audio. Une autre partie utilise du texte (descriptions de métadonnées de la musique et des sons) pour aider à déterminer le type d’audio généré.
Pour accélérer les choses, l’architecture Stable Audio fonctionne sur une représentation audio compressée et fortement simplifiée pour réduire le temps d’inférence (le temps nécessaire à un modèle d’apprentissage automatique pour générer une sortie une fois qu’il a reçu une entrée). Selon Stability AI, Stable Audio peut restituer 95 secondes d’audio stéréo 16 bits à une fréquence d’échantillonnage de 44,1 kHz (souvent appelée “Qualité du CD“) en moins d’une seconde sur un GPU Nvidia A100. L’A100 est un GPU de centre de données robuste conçu pour une utilisation par l’IA, et il est bien plus performant qu’un GPU de jeu de bureau classique.
Comme mentionné, Stable Audio n’est pas le premier générateur de musique basé sur des techniques de diffusion latente. En décembre dernier, nous avons couvert Riffusion, un amateur adopte une version audio de Stable Diffusion, bien que les générations résultantes soient loin des échantillons de Stable Audio en termes de qualité. En janvier, Google a publié MusiqueLMun générateur de musique IA pour l’audio 24 kHz, et Meta a lancé une suite d’outils audio open source (y compris un générateur de texte en musique) appelée AudioCraft en août. Désormais, avec un son stéréo de 44,1 kHz, Stable Diffusion fait monter la barre.
Stability indique que Stable Audio sera disponible dans un niveau gratuit et un forfait Pro mensuel de 12 $. Avec l’option gratuite, les utilisateurs peuvent générer jusqu’à 20 pistes par mois, chacune d’une durée maximale de 20 secondes. Le plan Pro étend ces limites, permettant 500 générations de pistes par mois et des durées de piste allant jusqu’à 90 secondes. Les futures versions de Stability devraient inclure des modèles open source basés sur l’architecture Stable Audio, ainsi qu’un code de formation pour ceux qui souhaitent développer des modèles de génération audio.
Dans l’état actuel des choses, il semble que nous soyons à la pointe de la musique générée par l’IA de qualité production avec Stable Audio, compte tenu de sa fidélité audio. Les musiciens seront-ils heureux s’ils sont remplacés par des modèles d’IA ? Probablement pas, si l’histoire nous a montré quelque chose depuis L’IA manifeste dans le domaine des arts visuels. Pour l’instant, un humain peut facilement surclasser tout ce que l’IA peut générer, mais cela ne sera peut-être pas le cas pour longtemps. Quoi qu’il en soit, l’audio généré par l’IA peut devenir un autre outil dans la boîte à outils de production audio d’un professionnel.









