
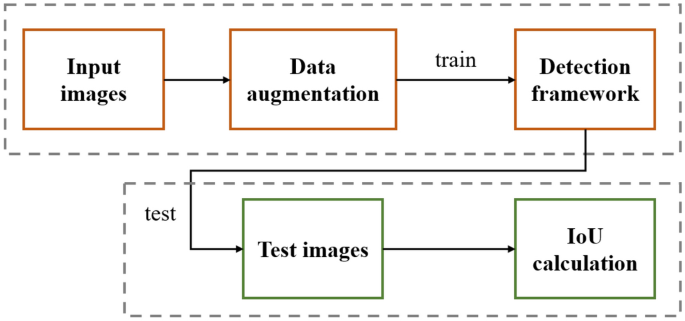
Cadre global
Le cadre global utilisé dans cet article est illustré à la figure 1. Premièrement, les images d’entrée sont d’abord soumises à une série d’augmentation de données, qui vise à étendre l’ensemble de données grâce à ce schéma, améliorant ainsi l’effet de formation et réduisant le surajustement. Deuxièmement, les images d’entrée enrichies de données sont introduites dans le cadre de détection pour la formation. Le cadre de détection est un détecteur sans ancre, qui ne nécessite pas d’ancre prédéfinie pour balayer l’image à mesurer, rendant ainsi son effet de détection indépendant des paramètres et réglages de l’ancre, etc., et obtenant des résultats plus robustes. Après la formation, le framework détecte l’image à mesurer afin que les résultats IoU soient calculés et que les résultats de détection finaux soient obtenus.
Organigramme global du cadre.
Augmentation des données
Les moyens d’augmentation des données comprennent une série de procédés. Tout d’abord, l’image est retournée horizontalement et verticalement pour agrandir l’image d’entrée d’origine d’un total de 4×. Deuxièmement, l’image est mise en miroir puis retournée horizontalement et verticalement pour obtenir une expansion totale de 8×.
En plus de l’augmentation des données de base, l’augmentation de la luminance et le recadrage aléatoire sont également utilisés. L’augmentation de la luminance fait référence à la modification aléatoire du paramètre de luminance de l’image d’entrée, tandis que la luminance est générée de manière aléatoire pour chaque entraînement, ce qui permet d’adapter efficacement le cadre de détection à chaque type d’image de test et ainsi d’obtenir de meilleurs résultats de détection. Le recadrage aléatoire signifie que l’image d’entrée est recadrée de manière aléatoire, c’est-à-dire que seules certaines informations sur l’image d’entrée sont conservées. Tout comme l’augmentation de la luminance, le recadrage aléatoire rend également l’entrée de formation différente pour chaque session de formation, rendant ainsi le cadre global plus robuste pour les tests.
Cadre de détection
L’un des problèmes les plus graves dans la détection d’objets est l’échelle incohérente de l’objet. Au cours des dernières années, un seul module d’extraction de caractéristiques a été appliqué aux détecteurs basés sur l’apprentissage profond, ce qui rend difficile la détection de tous les objets. Plus précisément, si le modèle bien entraîné montre de bonnes performances de détection sur les objets à grande échelle, les résultats de détection diminueront considérablement sur les objets à petite échelle. Par conséquent, un module de pyramide de fonctionnalités est adopté pour extraire des fonctionnalités à différentes échelles, ce qui a été vérifié par de nombreux frameworks de détection.
Le cadre de détection utilisé dans cet article est illustré à la figure 2. Tout d’abord, une image à mesurer est entrée dans un squelette à cinq couches, B1 à B5, puis chaque couche passe à travers un noyau de convolution 1 × 1 pour former un noyau de cinq couches. -pyramide de caractéristiques des couches, L1 à L5, où les foulées de chaque couche sont respectivement de 8, 16, 32, 64 et 128. Comme nous le savons tous, les tâches de détection d’objets comprennent deux sous-tâches : la classification et la localisation. Par conséquent, nous introduisons également un ensemble de têtes de détection à deux branches pour ces sous-tâches. Dans chaque tête de détection, un noyau convolutif 3 × 3 est transmis en premier, puis deux noyaux convolutifs 1 × 1 sont transmis pour prédire respectivement les deux branches.

Diagramme schématique du cadre de détection utilisé dans cet article.
Une série de fonctions de perte sont appliquées dans le cadre de détection. L’un d’eux concerne la prédiction CENTER, car elle est confrontée à un grave problème de déséquilibre de classes. En d’autres termes, comme le nombre de points CENTRE dans une image est très déséquilibré par rapport au nombre de points pixels en arrière-plan, il n’y a généralement que quelques points, voire aucun point dans un graphique qui appartiennent à la catégorie CENTRE. Par conséquent, la fonction traditionnelle de perte d’entropie croisée fonctionne généralement mal face à une telle situation. Sur cette base, cet article adopte une méthode de perte focale12 comme fonction de perte du centre :
$${L}_{center}=-frac{1}{N}sum_{i=1}^{W/r}{sum }_{j=1}^{H/r}{ alpha }_{ij}{left(1-{p}_{ij}right)}^{gamma }{text{log}}left({p}_{ij}right)$$
(1)
où ({p}_{ij}) est la probabilité de position (i, j), allant de 0 à 1. ({mathrm{alpha }}_{ij}) est le paramètre de poids.
En plus du centre, une perte Smooth L1 a également été appliquée aux prédictions d’échelle comme suit :
$${L}_{scale}=frac{1}{N}{sum }_{n=1}^{N}{text{Smooth}} {L}_{1}({s} _{n},g{t}_{n})$$
(2)
où N est le nombre d’objets à mesurer, s est le résultat prédit et gt représente l’étiquette de base.
Étant donné que les cinq têtes de détection entraînent et prédisent la carte des caractéristiques séparément, une certaine incertitude apparaît entre chaque tête de détection. Dans cet article, nous utilisons une stratégie de sélection, c’est-à-dire que le pas le plus grand dans le résultat de prédiction est utilisé comme meilleur résultat de détection pour la rétention. Étant donné que la taille des entités n’est pas cohérente dans chaque couche, nous définissons également la taille des cadres de délimitation dans chaque couche. Supposons que la distance maximale de la régression de la couche i sur un certain objet soit ({mi}) et le point de régression est (je, t, r, b). Si ({m}_{i}
Tests et calcul IoU
L’intersection sur union (IoU) est une mesure courante de la différence entre la boîte englobante testée et la boîte réelle dans la détection d’objets. En d’autres termes, plus le résultat IoU est grand, meilleur est le cadre de détection d’objets, et vice versa. L’IoU est calculé comme suit :
$$IoU=frac{Acap B}{Acup B}=frac{C}{A+BC}$$
(3)
Paramètres d’évaluation
La précision moyenne (AP), l’une des mesures expérimentales les plus couramment utilisées pour la détection d’objets, est adoptée dans cet article pour évaluer les performances de détection, qui sont définies comme suit :
$$Moyenne, Précision left(APright)={int }_{r=0}^{1}p(r)dr$$
où p(r) représente la courbe Précision-Rappel calculée via la matrice de confusion. En d’autres termes, AP est l’aire sous la courbe Précision-Rappel.
Parmi eux, AP, sans paramètres ni explications spéciales, utilise par défaut le nombre de trames détectées plus un si la trame de test et l’étiquette de vérité fondamentale sont considérées comme s’étant chevauchées à IoU > 0,5. De plus, l’AP communSAPM et APL Les métriques représentent respectivement les valeurs AP détectées pour les objets petits, moyens et grands. Puisqu’il n’y a pas de petit objet correspondant dans l’ensemble de données utilisé dans cet article, APM et APL sont utilisés comme métriques. De plus, ARdixARM et ARLqui sont des mesures du rappel moyen, sont également utilisées comme métriques expérimentales dans cet article.









