

Getty Images
Dans le monde de l’IA, ce que l’on pourrait appeler des « petits modèles de langage » ont récemment gagné en popularité car ils peuvent être exécutés sur un appareil local au lieu de nécessiter des ordinateurs de type centre de données dans le cloud. Mercredi, Apple introduit un ensemble de minuscules modèles de langage d’IA disponibles à la source, appelés OpenELM, suffisamment petits pour être exécutés directement sur un smartphone. Il s’agit pour l’instant principalement de modèles de recherche de validation de principe, mais ils pourraient constituer la base des futures offres d’IA sur appareil d’Apple.
Les nouveaux modèles d’IA d’Apple, collectivement nommés OpenELM pour « Open-source Efficient Language Models », sont actuellement disponibles sur le Visage câlin sous un Licence de code d’exemple Apple. Étant donné que la licence comporte certaines restrictions, elle peut ne pas correspondre au définition communément acceptée de “open source”, mais le code source d’OpenELM est disponible.
Mardi, nous avons couvert Les modèles Phi-3 de Microsoft, qui visent à atteindre quelque chose de similaire : un niveau utile de compréhension du langage et de performances de traitement dans de petits modèles d’IA pouvant s’exécuter localement. Phi-3-mini comporte 3,8 milliards de paramètres, mais certains modèles OpenELM d’Apple sont beaucoup plus petits, allant de 270 millions à 3 milliards de paramètres répartis en huit modèles distincts.
En comparaison, le plus grand modèle jamais sorti en Le lama de Meta 3 La famille comprend 70 milliards de paramètres (avec une version de 400 milliards en cours) et le GPT-3 d’OpenAI de 2020 est livré avec 175 milliards de paramètres. Le nombre de paramètres sert de mesure approximative de la capacité et de la complexité des modèles d’IA, mais des recherches récentes se sont concentrées sur la création de modèles de langage d’IA plus petits aussi performants que les plus grands l’étaient il y a quelques années.
Les huit modèles OpenELM sont disponibles en deux versions : quatre en version « pré-entraînée » (essentiellement une version brute du modèle avec le jeton suivant) et quatre en version optimisée pour les instructions (affinée pour le suivi des instructions, ce qui est plus idéal pour développer des assistants IA et chatbots) :
OpenELM propose une fenêtre contextuelle maximale de 2048 jetons. Les modèles ont été formés sur les ensembles de données accessibles au public Web raffinéune version de PILE une fois les doublons supprimés, un sous-ensemble de Pyjama Rougeet un sous-ensemble de Dolma v1.6, qui, selon Apple, totalise environ 1,8 billion de jetons de données. Les jetons sont des représentations fragmentées de données utilisées par les modèles de langage d’IA à des fins de traitement.
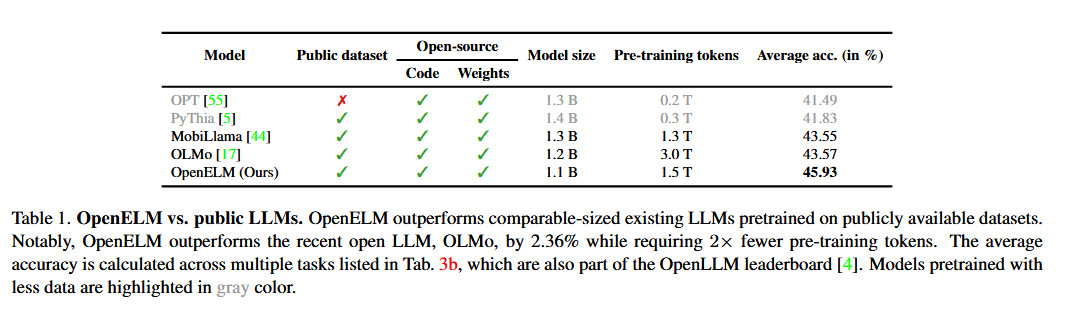
Apple affirme que son approche avec OpenELM inclut une « stratégie de mise à l’échelle par couche » qui allouerait les paramètres plus efficacement à chaque couche, économisant non seulement les ressources de calcul, mais améliorant également les performances du modèle tout en étant formé sur moins de jetons. Selon le communiqué d’Apple papier blanccette stratégie a permis à OpenELM d’obtenir une amélioration de 2,36 % en termes de précision par rapport à celle d’Allen AI. OLMo1B (un autre petit modèle de langage) tout en nécessitant deux fois moins de jetons de pré-formation.
Pomme
Apple a également publié le code pour CoreNet, une bibliothèque utilisée pour entraîner OpenELM, et qui comprenait également des recettes d’entraînement reproductibles qui permettent de répliquer les poids (fichiers de réseau neuronal), ce qui est jusqu’à présent inhabituel pour une grande entreprise technologique. Comme le dit Apple dans son résumé d’article OpenELM, la transparence est un objectif clé pour l’entreprise : « La reproductibilité et la transparence des grands modèles de langage sont cruciales pour faire progresser la recherche ouverte, garantir la fiabilité des résultats et permettre des enquêtes sur les biais des données et des modèles, comme ainsi que les risques potentiels.
En publiant le code source, les poids des modèles et le matériel de formation, Apple affirme vouloir « responsabiliser et enrichir la communauté de recherche ouverte ». Cependant, il prévient également que, puisque les modèles ont été formés sur des ensembles de données de source publique, « il existe la possibilité que ces modèles produisent des résultats inexacts, nuisibles, biaisés ou répréhensibles en réponse aux invites des utilisateurs ».
Bien qu’Apple n’ait pas encore intégré cette nouvelle vague de fonctionnalités de modèle de langage IA dans ses appareils grand public, la prochaine mise à jour iOS 18 (qui devrait être révélé en juin à la WWDC) inclurait de nouvelles fonctionnalités d’IA qui utiliser le traitement sur l’appareil pour garantir la confidentialité des utilisateurs, même si l’entreprise peut potentiellement embaucher Google ou OpenAI pour gérer un traitement d’IA hors appareil plus complexe afin de donner à Siri un coup de pouce attendu depuis longtemps.









