

“Le sanskrit convient au langage des ordinateurs et ceux qui apprennent l’intelligence artificielle l’apprennent”, a déclaré le président de l’Indian Space Research Organization. S. Somanath a dit lors d’un événement à Ujjain le 25 mai. Il s’agissait de la dernière d’une série de déclarations exaltant le sanskrit et sa valeur pour l’informatique, mais sans aucune preuve ni explication.
Mais au-delà du sanskrit, comment les autres langues indiennes s’en sortent-elles dans le domaine de l’intelligence artificielle (IA), à une époque où ses applications basées sur la langue ont pris d’assaut le monde ?
La réponse est un sac mélangé. Il existe une certaine discrimination passive alors même que le destin des langues est porté par la recherche et l’innovation citoyennes.
À l’intérieur de ChatGPT
Derrière les chatbots apparemment intelligents et les ordinateurs de création artistique, les algorithmes et les techniques de manipulation de données transforment les données linguistiques et visuelles en objets mathématiques (comme des vecteurs) et les combinent de manière spécifique pour produire le résultat souhaité. C’est ainsi que ChatGPT est en mesure de répondre à vos questions.
Lorsqu’elle travaille avec une langue, une machine doit d’abord décomposer une phrase ou un mot en petits morceaux dans un processus appelé tokenisation. Ce sont les bits avec lesquels le modèle de traitement de données de la machine fonctionnera. Par exemple, « il y a une étoile » peut être symbolisé par « là », « est », « une » et « étoile ».
Il existe plusieurs techniques de tokenisation. Un treebank tokeniser décompose les mots et les phrases en fonction des règles que les linguistes utilisent pour les étudier. Un tokeniseur de sous-mots permet au modèle d’apprendre un mot commun et des modifications à ce mot séparément, comme “poussiéreux” et “plus poussiéreux”/”le plus poussiéreux”.
OpenAI, le créateur de ChatGPT et de la série GPT de grands modèles de langage, utilise un type de jeton de sous-mot appelé codage par paire d’octets (BPE). Voici un exemple de API OpenAI en utilisant ceci sur une déclaration de Gayathri Chakravorty Spivak :
anglais v. Non
En 2022, Amazon a publié une base de données parallèle d’un million d’énoncés dans 52 langues, appelé MASSIF. « Parallèle » signifie que le même énoncé est présenté dans plusieurs langues. Un énoncé peut être une simple requête ou une phrase. Par exemple, non. 38 dans le Section tamoule est “La luminosité de mon écran est-elle faible ?” – signifiant « la luminosité de mon écran me semble-t-elle faible ? ».
Le 3 mai de cette année, La chercheuse en intelligence artificielle Yennie Jun a combiné l’API OpenAI et MASSIVE pour analyser comment BPE symboliserait 2 033 phrases dans les 52 langues.
Mme Jun a constaté que les phrases en hindi étaient symbolisées en moyenne en 4,8 fois plus de jetons que leurs phrases en anglais correspondantes. De même, les jetons pour les phrases en ourdou étaient 4,4 x plus longs et pour le bengali, 5,8 x plus longs. L’exécution d’un modèle avec plus de jetons augmente son coût opérationnel et sa consommation de ressources.
GPT et ChatGPT peuvent également admettre un nombre fixe de jetons d’entrée à la fois, ce qui signifie que leur capacité à analyser le texte anglais est meilleure que d’analyser l’hindi, le bengali, le tamoul, etc. Mme Jun a écrit que cela est important car ChatGPT a été largement utilisé. adopté “dans diverses applications (des plateformes d’apprentissage des langues comme Duolingo aux applications de médias sociaux comme Snapchat)”, soulignant “l’importance de comprendre les nuances de la tokenisation pour assurer un traitement équitable du langage dans diverses communautés linguistiques”.
ChatGPT peut basculer
En règle générale, l’expert en intelligence artificielle Viraj Kulkarni a déclaré qu’il est “assez difficile” pour un modèle formé pour travailler avec l’anglais d’être adapté pour travailler avec une langue avec une grammaire différente, comme l’hindi.
« Si vous prenez [an English-based] modéliser et l’affiner à l’aide d’un corpus hindi, le modèle pourra peut-être réutiliser une partie de sa compréhension de la grammaire anglaise, mais il devra encore apprendre les représentations de mots hindis individuels et les relations entre eux », a déclaré le Dr Kulkarni, chef scientifique des données chez DeepTek AI, basé à Pune, a déclaré.
Des phrases dans différentes langues sont ainsi symbolisées de différentes manières, même si elles ont le même sens. Voici la déclaration du Dr Spivak en allemand, grâce à Google Traduction :
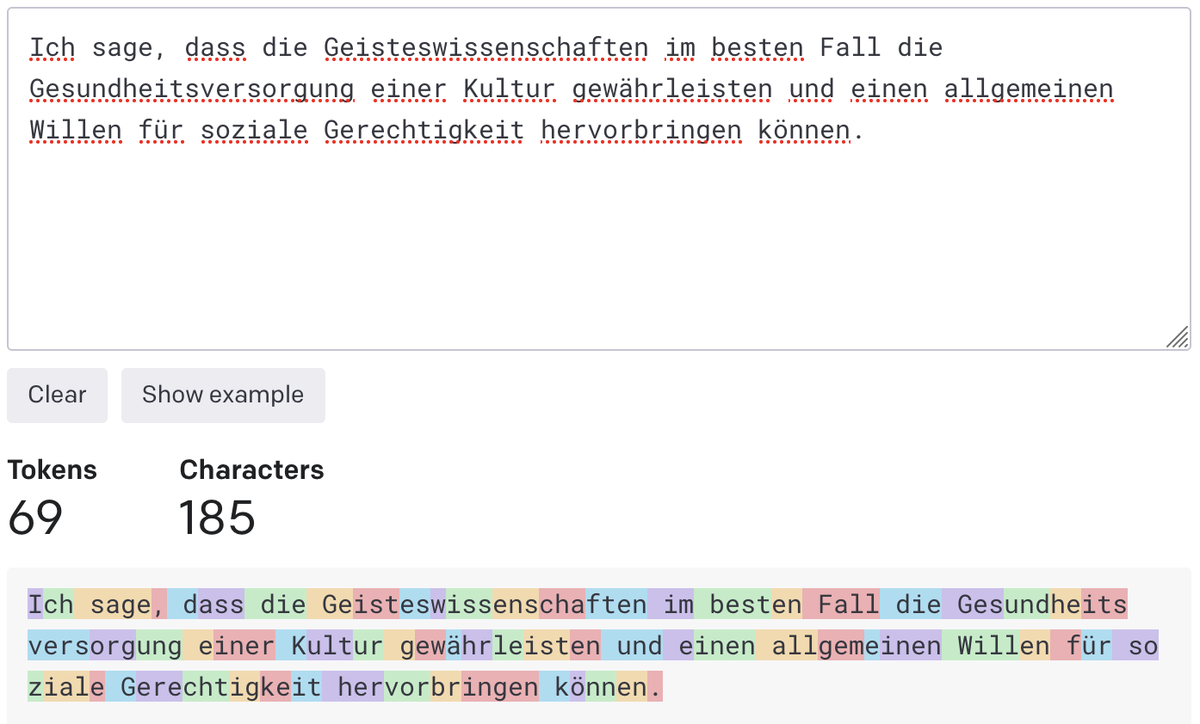
Cela dit, ChatGPT en particulier ne se débat pas avec d’autres langues. Selon le Dr Kulkarni, GPT-4, qui alimente la version premium de ChatGPT, a été formé en anglais ainsi que “presque la plupart des principales langues du monde, [so it] n’a aucune préférence pour l’anglais ou toute autre langue.
“Il est peut-être meilleur en anglais qu’en hindi car il a peut-être vu plus de textes en anglais que de textes en hindi, mais il peut basculer de manière très fluide entre les langues”, a-t-il ajouté.

Viraj Kulkarni demande à GPT-4 d’écrire une courte note sur l’IA en hindi. , Crédit photo : Viraj Kulkarni/Arrangement spécial
Mais il y a toujours une différence de coût. En janvier 2023, expert en machine learning Denys Linkov envoyé les 50 premiers énoncés en anglais dans MASSIVE à ChatGPT avec une invite : “Réécrivez la phrase suivante sur un ton plus amical”. Il a répété la tâche avec les 50 premiers énoncés en malayalam. Il a constaté que ce dernier utilisait 15,69 fois plus de jetons.
OpenAI facture un tarif fixe pour utiliser ChatGPT en fonction du nombre de jetons, de sorte que Malayalam était également 15,69 fois plus cher.
De plus en plus de données
Cela dit, pour les modèles conçus pour fonctionner avec des langues individuelles, l’adaptation pourrait être un problème – comme tout langage qui n’a pas beaucoup de matériel indexé disponible pour le modèle avec lequel s’entraîner. C’est le cas de nombreuses langues indiennes.
« Les percées récentes indiquent sans équivoque que les gains les plus importants en [model] les performances ne proviennent que de deux facteurs : la taille du réseau, ou le nombre de paramètres, et la taille des données d’entraînement », selon le Dr Kulkarni.
Un paramètre est une façon dont les mots peuvent être différents les uns des autres. Par exemple, le type de mot (verbes, adjectifs, noms, etc.) peut être un paramètre et le temps peut en être un autre. GPT-4 a des milliards de paramètres. Plus un modèle a de paramètres, meilleures sont ses capacités.
La quantité de données de formation pour l’anglais est beaucoup plus importante que celle pour les langues indiennes. ChatGPT a été formé sur du texte extrait d’Internet – un endroit où environ 55% du contenu est en anglais. Le reste c’est toutes les autres langues du monde combiné. Peut-il suffire ?
Nous ne savons pas. Selon le Dr Kulkarni, il n’y a pas de “taille minimale” connue pour un ensemble de données d’entraînement. « La taille minimale dépend aussi de la taille du réseau », a-t-il expliqué. “Un grand réseau est plus puissant, peut représenter des fonctions plus complexes et a besoin de plus de données pour atteindre ses performances maximales.”
Données pour ‘affiner’
“La disponibilité du texte dans chaque langue va être une longue traîne – quelques langues avec beaucoup de texte, de nombreuses langues avec peu d’exemples” – et cela va affecter les modèles traitant de cette dernière, Makarand Tapaswi, une machine senior a déclaré un scientifique en apprentissage à Wadhwani AI, une organisation à but non lucratif, et professeur adjoint au groupe de vision par ordinateur de l’IIIT Hyderabad.
“Pour les langues rares”, a-t-il ajouté, le modèle pourrait d’abord traduire les mots en anglais, trouver la réponse, puis retraduire vers la langue d’origine, “ce qui peut également être une source d’erreurs”.
“En plus des tâches de prédiction du mot suivant, les modèles de type GPT ont encore besoin d’une certaine personnalisation pour s’assurer qu’ils peuvent suivre les instructions en langage naturel, mener des conversations, s’aligner sur les valeurs humaines, etc.”, a déclaré Anoop Kunchukuttan, chercheur chez Microsoft. . « Les données pour cette personnalisation, appelée « réglage fin », doivent être de haute qualité et sont toujours disponibles principalement en anglais uniquement. Une partie de cela existe pour les langues indiennes, [while] des données pour la plupart des types de tâches complexes doivent être créées.
MASSIVE d’Amazon est un pas dans cette direction. D’autres incluent Google Jeu de données ‘Dakshina’ avec des scripts pour une douzaine de langues sud-asiatiques ; et l’open source “Aucune langue laissée de côté” programme, pour créer des « ensembles de données et des modèles » qui réduisent « l’écart de performances entre les langages à ressources faibles et élevées ».
Rencontrez AI4Bharat
En Inde, AI4Bharat est une initiative de l’IIT Madras qui “construit une IA de langage open source pour les langues indiennes, y compris des ensembles de données, des modèles et des applications”, selon son site internet.
Le Dr Kunchukuttan est membre fondateur et co-directeur du Centre Nilekani à AI4Bharat. Pour former des modèles de langage, a-t-il dit, AI4Bharat dispose d’un corpus appelé IndicCorp avec 22 langues indiennes, et son robot d’exploration de sites Web CommonCrawl peut prendre en charge « 10 à 15 langues indiennes ».
Une partie du traitement du langage naturel est le langage naturel compréhension (NLU) – dans lequel un modèle fonctionne avec le sens d’une phrase. Par exemple, lorsqu’on lui demande “quelle est la température à Chennai ?”, un modèle NLU peut effectuer trois tâches : identifier qu’il s’agit d’une question liée à la météo (1) nécessitant une réponse (2) concernant une ville (3).
En décembre 2022 papier préimprimé (mis à jour le 24 mai 2023), les chercheurs d’AI4Bharat ont rapporté une nouvelle référence pour les langues indiennes appelée “IndicXTREME”. Ils ont écrit qu’IndicXTREME a neuf tâches NLU pour 20 langues dans la huitième annexe de la Constitution, dont neuf pour lesquelles il n’y a pas assez de ressources pour former des modèles de langue. Il permet aux chercheurs d’évaluer les performances des modèles qui ont « appris » ces langages.
Modèles de taille modeste
La préparation de tels outils est laborieuse. Par exemple, le 25 mai, AI4Bharat rendu public ‘Bharat Parallel Corpus Collection’, “le plus grand corpus parallèle accessible au public pour les langues indiennes”. Il contient 23 crores de paires de textes ; parmi ceux-ci, 6,44 lakh ont été “traduits manuellement”.
Ces outils doivent également tenir compte des dialectes, des stéréotypes, de l’argot et des références contextuelles basées sur caste, religion et région.
Les techniques informatiques peuvent aider à faciliter le développement. Dans un 9 mai papier préimpriméun groupe AI4Bharat a abordé “la tâche de la traduction automatique d’une langue à ressources extrêmement limitées vers l’anglais en utilisant le transfert interlinguistique à partir d’une langue à ressources élevées étroitement liée”.
“Je pense que nous sommes à un point où nous avons des données pour former des modèles de taille modeste pour les langues indiennes et commencer à expérimenter les directions … mentionnées ci-dessus”, a déclaré le Dr Kunchukuttan. “Il y a eu une poussée d’activité de modèles open source de taille modeste en anglais, et cela indique que nous pourrions construire des modèles prometteurs pour les langues indiennes, ce qui devient un tremplin pour de nouvelles innovations.”









